Summer is quietly coming to an end. As Google Summer of Code (GSoC) 2025 wraps up, it’s time to hand in my summer homework — this GSoC final report.
My GSoC project: Zeno v2 Enhancement Proposal: Headless Mode, CSS Parser, and More – Google Summer of Code
A quick intro to Zeno: Zeno is the Internet Archive’s self-described state-of-the-art WARC web archiver, and as far as I know, the only Golang WARC archiver to date.
Starting with the least meaningful metric: from June 2 (GSoC Coding officially begins) to August 31 (near the end), roughly 90 days, I opened 25 PRs to Zeno: 23 merged, 2 open. I also sent PRs to gowarc (Zeno’s WARC read/write/recording library) and gocrawlhq (Zeno’s tracker client), plus a few PRs to external dependencies.
Here are some of the more interesting bits along the way.
CSS, the myth

Regex master
As we all know, CSS can reference external URLs. For example, adding a background image via CSS:
body {
background: url(http://example.com/background.jpg);
}Zeno parses inline CSS inside HTML and tries to extract values from URL tokens and string tokens using regex. The two simple regexes looked like this:
urlRegex = regexp.MustCompile(`(?m)url\((.*?)\)`)
backgroundImageRegex = regexp.MustCompile(`(?:\(['"]?)(.*?)(?:['"]?\))`)The biggest issue was that the second one, backgroundImageRegex, was far too permissive — it matched anything inside parentheses.
This meant Zeno often parsed a lot of nonexistent relative paths from inline CSS. For example, in color: rgb(12, 34, 56), the 12, 34, 56 inside the parentheses got matched, causing Zeno to crawl a bunch of annoying 404 asset URLs.
How do we fix this? Write an even cleverer regex? I’d rather not become a regex grandmaster. Let’s use a real CSS parser.
A proper CSS parser should correctly handle token escaping and other housekeeping.
What in CSS actually makes network requests?
Before picking a CSS parser, I first asked: “For an archival crawler, which CSS constructs can contain useful external resources?”
Looking at CSS Values and Units Module Level 4, the Security Considerations section states:
This specification defines the
url()andsrc()functions (<url>), which allow CSS to make network requests.
However, for security reasons, src() is not implemented by any browser yet, so we can ignore it for now.
Note a special case for @import: the string token after @import should be treated as if it were url(""). For example, these two rules are equivalent:
@import "mystyle.css";
@import url("mystyle.css");So the only CSS tokens that can initiate network requests (without JS) are url() and the string token following @import.
There are two flavors of
url():
- The older unquoted form:
url(http://example.com)– a URL token- The quoted form (single or double quotes):
url("http://example.com")– a function token plus a string tokenTheir parsing/escaping differs. In this report, “URL token” refers to both.
CSS parser
With the spec in mind, I surveyed Go CSS parser libraries. The only one that seemed somewhat viable was https://github.com/tdewolff/parse — widely used, looks decent. But hands-on testing was a wake-up call.
It doesn’t decode token values; it’s more of a lexer/tokenizer. Not quite enough.
For instance, it can only give you the whole token like url( "http://a\"b.c" ) — you get out what you put in — but it can’t decode the value to http://a"b.c.
Other Golang CSS parsers were even less helpful.
So I wrote a small parser dedicated to extracting URL-token values, focusing on escapes, newlines, and whitespace. Then I wired it up with tdewolff/parse.
PR: #324 Replacing the regex-based CSS extractor with a standard CSS parser
I also added a simple state machine to extract URLs from @import.
Note: `@import` is only valid in the stylesheet header; occurrences elsewhere should be ignored. Not critical, but easy enough, so I implemented it.PR: #339 Extracting URLs from CSS @import rule
Living on a tree
In Zeno, each URL crawl task is called an item. Every item has its own type and state.
type Item struct {
id string // ID is the unique identifier of the item
url *url.URL {
mimetype *mimetype.MIME
Hops int // This determines the number of hops this item is the result of, a hop is a "jump" from 1 page to another page
Redirects int
}
status ItemState // Status is the state of the item in the pipeline
children []*Item // Children is a slice of Item created from this item
parent *Item // Parent is the parent of the item (will be nil if the item is a seed)
}Briefly, Hops is the page depth, and Redirects is the number of redirects followed.
Items form a tree. A root item with no parent is a seed item (a page/outlink), while all descendants are asset items (resources).
For example, if we archive archive.org, that item is the seed. On the page we discover archive.org/a.jpg as an asset; we add it to item.children. We also find archive.org/about as an outlink, so we create a separate seed item; that new seed’s hops += 1.
We know HTML has inline CSS, but it also references standalone CSS via <link rel="stylesheet" href="a.css">.
Previously, Zeno struggled on pages with separate CSS files (i.e., most pages), not only due to the lack of a proper CSS parser, but also because resources referenced inside CSS are assets of an asset — the seed item (HTML) → asset item (CSS file) → asset (e.g., images). Zeno generally doesn’t extract assets-of-assets.
My change was to integrate the parser above and then open a “backdoor” for CSS that is an asset of HTML: when item.mimetype == CSS && item.parent.mimetype == HTML, allow that asset item to extract its own assets. (We also need a backdoor for HTML → CSS → CSS via @import; see below.)
Was that enough? Not quite.
CSS Nesting
While developing, I found tdewolff/parse doesn’t support CSS Nesting, a “new” feature introduced in 2013.
To handle CSS that uses the nesting sugar as best as possible, I donned the regex robe again and added a smarter regex fallback parser to kick in when tdewolff/parse fails.
cGroup = `(.*?)`
cssURLRegex = regexp.MustCompile(`(?i:url\(\s*['"]?)` + cGroup + `(?:['"]?\s*\))`)
cssAtImportRegex = regexp.MustCompile(`(?i:@import\s+)` + // start with @import
`(?i:` +
`url\(\s*['"]?` + cGroup + `["']?\s*\)` + // url token
`|` + // OR
`\s*['"]` + cGroup + `["']` + `)`, // string token
)Done now? Still not.
Endless @import
From https://www.w3.org/TR/css-cascade-5/#at-ruledef-import:
The @import rule allows users to import style rules from other style sheets. If an @import rule refers to a valid stylesheet, user agents must treat the contents of the stylesheet as if they were written in place of the @import rule
“In place” is interesting. It made me wonder: if a page recursively @imports forever, what do browsers do? The spec doesn’t mention a depth limit. Do real browsers cap @import depth like they cap redirect chains?
I tested it: browsers don’t enforce a recursion limit for @import.
So you can even make a page that never finishes loading, lol.
To prevent a CSS @import DoS on Zeno (unlikely, but let’s be safe), I added a --max-css-jump option to limit recursion depth.
PR: #345 Cascadingly capture css @import urls and extracting urls from separate css item
Also, the CSS spec says: when resolving ref URLs inside a separate CSS file, the base URL should be the CSS file’s URL, not the HTML document’s base. Thanks to Zeno’s item tree design, this came for free — no special handling needed in the PR.
Firefox is wrong
This section isn’t about Zeno — it’s just a quirky inconsistency I noticed while reading the CSS spec. Fun trivia.
First, look at the escape handling for string tokens.
U+005C REVERSE SOLIDUS (\)
1. If the next input code point is EOF, do nothing.
2. Otherwise, if the next input code point is a newline, consume it.
3. Otherwise, (the stream starts with a valid escape) consume an escaped code point and append the returned code point to the <string-token>’s value.If a backslash in a string token is followed by EOF, do nothing (i.e., ignore the escape and return the token as-is).
But if a backslash is followed by a valid escape, proceed with escape handling.
Checking whether an escape is valid looks at the backslash and the next code point: https://www.w3.org/TR/css-syntax-3/#check-if-two-code-points-are-a-valid-escape
If the first code point is not U+005C REVERSE SOLIDUS (\), return false.
Otherwise, if the second code point is a newline, return false.
Otherwise, return true.So for string tokens, as long as the next code point is not EOF and not a newline, it’s considered a valid escape.
Escape consumption: https://www.w3.org/TR/css-syntax-3/#consume-an-escaped-code-point
This section describes how to consume an escaped code point. It assumes that the U+005C REVERSE SOLIDUS (\) has already been consumed and that the next input code point has already been verified to be part of a valid escape. It will return a code point.
Consume the next input code point.
1. hex digit
Consume as many hex digits as possible, but no more than 5. Note that this means 1-6 hex digits have been consumed in total. If the next input code point is whitespace, consume it as well. Interpret the hex digits as a hexadecimal number. If this number is zero, or is for a surrogate, or is greater than the maximum allowed code point, return U+FFFD REPLACEMENT CHARACTER (�). Otherwise, return the code point with that value.
2. EOF
This is a parse error. Return U+FFFD REPLACEMENT CHARACTER (�).
3. anything else
Return the current input code point.It consumes up to 6 hex digits. If 1–6 hex digits were consumed and the next code point is whitespace, it swallows that whitespace as part of the escape (see https://www.w3.org/International/questions/qa-escapes#cssescapes).
If no hex digits are consumed, it returns the current code point unchanged. If it encounters EOF, it returns U+FFFD.
Here’s the issue: in the branch with zero hex digits, this algorithm can’t encounter EOF — because the prior “valid escape” check needs a next code point, which excludes EOF.
So which rule wins in the overall tokenization? Do we follow the higher-level “Consume a token” rule (backslash + EOF in a string does nothing), or the escape rule (backslash + EOF returns U+FFFD)?
Turns out people noticed this in 2013: https://github.com/w3c/csswg-drafts/issues/3182
Browsers disagree too.
- Chrome and Safari return
�. - Firefox returns
\�.
W3C’s resolution: “\[EOF] turns into U+FFFD except when inside a string, in which case it just gets dropped.”
Even today, browsers aren’t fully aligned here. See WPT: https://wpt.live/css/css-syntax/escaped-eof.html
VS Code
See @overflowcat’s post: A CSS variable, a hidden change in spec, and a VS Code fix
A CSS lexer from Blink
On August 5, @renbaoshuo said he had ported Blink’s CSS lexer to Go, named go-css-lexer.
See @renbaoshuo’s post: https://blog.baoshuo.ren/post/css-lexer/
As you’ve gathered above, usable CSS lexers/parsers for Go are scarce. This was promising — and it is. I made a small performance optimization, replaced tdewolff/parse and the regex fallback with it, and it’s been working great. CSS Nesting and custom CSS variables are fine.
PR: renbaoshuo/go-css-lexer#1 Performance optimization
PR: #415 New CSS parser with go-css-lexer
Headless
Two years ago, in Zeno#55, we tried to implement headless browsing using Rod.
Rod is a high-level driver for the DevTools Protocol. It’s widely used for web automation and scraping. Rod can automate most things in the browser that can be done manually.
But there was concern that the Chrome DevTools Protocol (CDP) might manipulate network data (e.g., tweak HTTP headers, transparently decompress payloads), so #55 was put on hold.
After skimming Rod’s request hijacking code, I saw it operates outside CDP. I confirmed with the Rod maintainer that an external http.Client (our gowarc client) can have full control over Chromium’s network requests.
Hijacking Requests | Respond with ctx.LoadResponse():
* As documented here: <https://go-rod.github.io/#/network/README?id=hijack-requests>
* The http.Client passed to ctx.LoadResponse() operates outside of the CDP.
* This means the http.Client has complete control over the network req/resp, allowing access to the original, unprocessed data.
* The flow is like this: browser --request-> rod ---> server ---> rod --response-> browserUsing CDP as a MITM beats general HTTP/socket-based mitmproxy approaches in one dimension: you can control requests per tab with finer granularity.
So, let’s build it.
I thought it would take a week. It took over two months, mostly ironing out details.
PR: https://github.com/internetarchive/Zeno/pull/356
Scrolling
Lazy loading has been common since the pre-modern web, and modern sites increasingly load content dynamically.
So once a page “finishes” loading, the first thing is to scroll to trigger additional resource loads. Scrolling well is an art:
- Each scroll step shouldn’t exceed the tab’s viewport height, or you’ll skip elements.
- Scroll too fast and some fixed-rate animations won’t fully display, losing chances to load resources.
- Scroll too slow and you waste time; headless is heavy — keeping tabs alive is costly.
- It should be silky smooth.
Rather than reinventing this, I recalled webrecorder’s archiver auto-scrolls. Indeed, webrecorder/browsertrix-behaviors provides a simple heuristic scroller and many other useful behaviors (auto-play media, auto-click, etc.), all bundled as a single JS payload. Perfect — drop it in.
DOM
Traditional crawlers work with raw HTML per request.
In a browser, everything is the DOM. A tab’s DOM tree results from the server’s HTML response, the browser’s HTML normalization, JS DOM manipulation, and even your extensions.
Open a direct .mp4 URL and the browser actually creates an HTML container to play it, e.g.:
<html>
<head><meta name="viewport" content="width=device-width"></head>
<body><video controls="" autoplay="" name="media"><source src="{URL}" type="video/mp4"></video></body>
</html>To keep Zeno’s existing outlink post-processing compatible (so we can extract outlinks from headless runs), I export the tab’s DOM as HTML and stash it in item.body, letting our current outlink extractors run with minimal changes.
nf_conntrack bites back
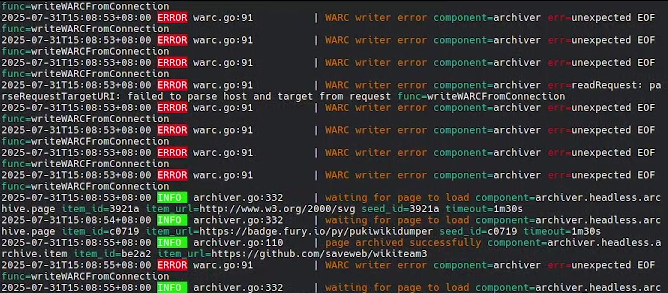
After finishing headless outlink crawling, I noticed that under high concurrency, new connections started failing with mysterious Connection EOFs, spiraling into death-retries. It looked like a race, and I chased it on and off for a couple of weeks. dmesg was clean; fs.file-max was fine.
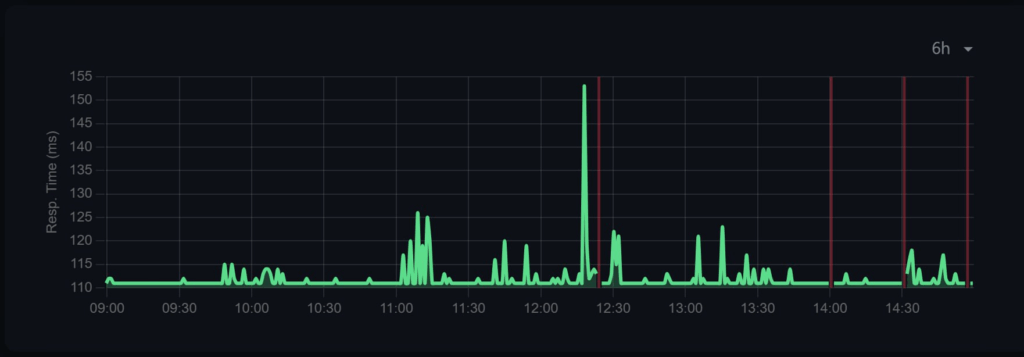
By chance I discovered my upstream device’s occasional outages aligned with my headless tests…
Thanks to @olver for setting up monitoring.

- gowarc doesn’t implement HTTP/1.1 keep-alive (and no HTTP/2 yet).
- Zeno opens a new connection for each request.
- Conntrack keeps entries around for a while after connections close.
- The egress router only has 512MB RAM; Linux auto-set
nf_conntrack_maxto 4096. - Headless Zeno generates a lot of requests.
- When the conntrack table fills up, new connections are dropped; existing ones keep working. My chat apps stayed online, so I didn’t notice.
Raising nf_conntrack_max on the router fixed it.
Future work:
I worry Zeno might also exhaust target servers’ TCP connection pools under high concurrency. The real fix is connection reuse:
- Support HTTP/1.1 keep-alive.
- Support HTTP/2.
HTTP caching
- Chromium’s HTTP caching (RFC 9111) lives in the net stack.
- We bypass Chromium’s net stack via CDP to use our own
gowarcHTTP client.
As a result, every tab re-downloads cacheable resources (JS, CSS, images…). Implementing a full HTTP cache in Zeno would be a lot of work just to save bandwidth.
Fortunately, CDP exposes the resource type in request metadata. If we’ve seen an URL before and it’s an image, CSS, font, etc., we can block it. For cacheable static HTML/JS, we have to let them through for the page to load correctly.
isSeen := seencheck(item, seed, hijack.Request.URL().String())
if isSeen {
resType := hijack.Request.Type()
switch resType {
case proto.NetworkResourceTypeImage, proto.NetworkResourceTypeMedia, proto.NetworkResourceTypeFont, proto.NetworkResourceTypeStylesheet:
logger.Debug("request has been seen before and is a discardable resource. Skipping it", "type", resType)
hijack.Response.Fail(proto.NetworkErrorReasonBlockedByClient)
return
default:
logger.Debug("request has been seen before, but is not a discardable resource. Continuing with the request", "type", resType)
}
}This isn’t “standard” like a real HTTP cache, and headful previews will look incomplete, but it’s simple, effective, and doesn’t hurt replay quality. Based on HTTP Archive’s Page Weight stats, a back-of-the-envelope estimate suggests it saves about 44% of traffic.
Future work:
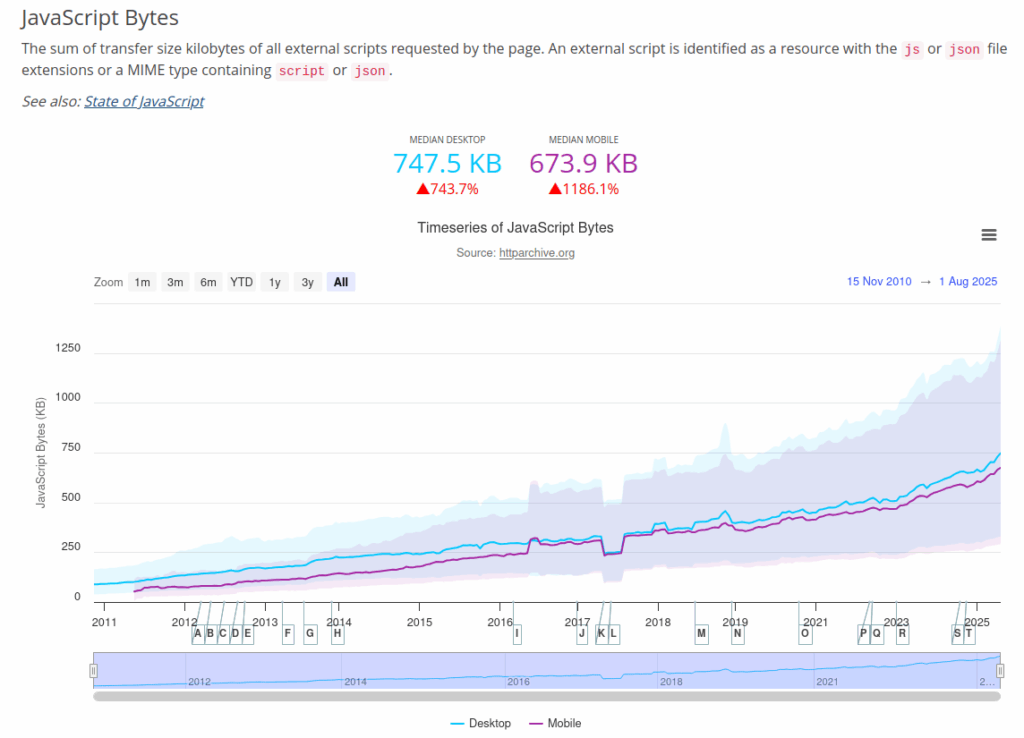
Compared to other asset types, JavaScript payloads have been trending upward.
We could implement an HTTP cache for headless in Zeno to save JS bandwidth.
Chromium revision
Rod’s default Chromium revision is too old. I switched to fetching the latest snapshot revision from chromiumdash.appspot.com and downloading the matching binary.
Sometimes Google publishes a version number on chromiumdash but doesn’t build a binary for it. So, like Rod, we pinned a default revision in Zeno.
I also found some WAFs block snapshot Chromium builds but ignore distro-packaged release builds. For production, it’s best to use the distro’s Chromium.
Q: Why not use Google Chrome binaries?
A: Zeno is open source, and Google Chrome is not. It’s a mismatch.
Q: Doesn’t Google ship release builds of Chromium?
A: Only automated snapshot builds.Content-Length and HTTP connections
When Zeno starts a crawl and free disk space drops too low, the diskWatcher signals workers to pause new items, but in-flight downloads continue until they finish.
If, at the moment of the pause, the total size of in-flight downloads exceeds --min-space-required, we’ll still run out of space — kaboom.
So I added --max-content-length. Before downloading, we check the Content-Length header; if it exceeds the cap, we skip. For streaming responses with unknown length, if the downloaded size crosses the cap, we abort.
PR: https://github.com/internetarchive/Zeno/pull/369
While working on this, I found three connection-related bugs in gowarc:
- A critical one: when the HTTP TCP connection closes abnormally (early EOF, I/O timeout, conn closed/reset), gowarc called
.Close()instead of.CloseWithError(). The downstream mirrored MITM TCP connection mistook it for a normal EOF. For streaming responses withoutContent-Length, these early-EOF responses were treated as valid and written into WARC, compromising data integrity for all streaming responses. (For non-streaming responses withContent-Length, Go’shttp.ReadResponse()usesio.LimitReaderand checks that EOF aligns withContent-Length; if mismatched, it returns an early EOF. In other words, the stdlib masked this in most cases.) --http-read-deadlinehad no effect.- On errors, temp files were sometimes not deleted.
Since Zeno defaults to Accept-Encoding: gzip, many servers return gzipped HTML/CSS/JS, often as streaming payloads. The impact was broad.
Bugfixes PR: https://github.com/internetarchive/gowarc/pull/115
Future work:
I also planned a --min-space-urgent option to abort all in-flight downloads when disk space is critically low. I got too excited fixing the bugs and forgot. Next time.
E2E tests
Web crawlers face the real internet. Zeno used to have only unit tests, with no integration or E2E tests exercising end-to-end behavior.
I’d heard Kubernetes’ E2E tests are the gold standard in Go land, but staring at https://github.com/kubernetes-sigs/e2e-framework didn’t help — I still didn’t know how to wire E2E for Zeno. How to instrument it? How to assert components behave as expected?
I came up with a log-based E2E approach. I couldn’t think of a more non-intrusive way.
During go test, spin up Zeno’s main in-process, redirect logs to a socket, and let Zeno run the test workload we feed it. The test suite connects to the socket, streams logs, and asserts lines we expect (or don’t expect).
This requires no instrumentation or mocking — logs are the probe.
To get coverage and race detector benefits over the code under test, we don’t exec a separate binary; we invoke the main entry point from a Test* function. Since go test builds all tests in the same package into one binary and runs them in one process, each E2E test must live in a different package.
PR: https://github.com/internetarchive/Zeno/pull/403
Later I realized we were in one process, so we didn’t need sockets for “cross-process” comms; I switched to a simpler
io.Pipe.
Future work:
Increase coverage. Since adding E2E tests, Zeno’s coverage slowly climbed from 51% to 56%. While 100% isn’t realistic for a crawler, getting to ~70% would significantly boost confidence when making changes.
Pulling your head out of the UTF‑8 sand
It does not make sense to have a string without knowing what encoding it uses. You can no longer stick your head in the sand and pretend that “plain” text is ASCII.
There Ain’t No Such Thing As Plain Text.
As of 2025‑08‑30, 98.8% of websites use UTF‑8. Zeno previously didn’t treat non‑UTF‑8 HTML specially.
If Zeno were a general-purpose crawler, we could ignore the remaining 1.2%. But as a web archiver, those legacy-encoded sites that survived into the present are valuable and charmingly retro.
Implementation was straightforward: follow WHATWG specs step by step and add tests.
The specs smell like legacy, too:
https://html.spec.whatwg.org/multipage/urls-and-fetching.html#resolving-urls
Let encoding be UTF-8.
If environment is a Document object, then set [encoding] (document charset) to environment's character encoding.
https://url.spec.whatwg.org/#query-state
1. ....
2. Percent-encode after encoding, with [encoding], buffer, and queryPercentEncodeSet, and append the result to url’s query.
https://url.spec.whatwg.org/#path-state
1. If ...special cases...
2. Otherwise, run these steps:
.... special cases ...
3. UTF-8 percent-encode c using the path percent-encode set and append the result to buffer.If the document charset is non‑UTF‑8, then when encoding a URL: the path is UTF‑8 percent-encoded, but the query is percent-encoded using the document’s charset. Quirky? Yep.
PR: https://github.com/internetarchive/Zeno/pull/370
Goada
ada is a C++ URL parser compatible with WHATWG standards. It has Go bindings: goada. Zeno uses it to normalize URLs (Go’s stdlib net/url isn’t WHATWG-compatible). But since goada is C++, building Zeno requires CGO, which complicates cross-compilation.
@otkd tried replacing goada with pure Go nlnwa/whatwg-url (Zeno#374), but I found that on non‑UTF‑8 input it bluntly replaces bytes with U+FFFD before percent-encoding, instead of percent-encoding the raw bytes.
Before normalization we can’t assume input URLs are valid UTF‑8, and for non‑UTF‑8 HTML/URLs we need the parser to percent-encode bytes as-is (as WHATWG requires), so #374 was closed.
fun fact: goada package c bindings were updated to the latest ada package as part of our exploration into using a different URL parser.
Future work:
goada is excellent quality. If only it didn’t require CGO. We could try packaging ada as WASM (e.g., like ncruces/go-sqlite3) using wazero to avoid CGO.
Misc
Lots of small PRs not worth detailing: terminal colors 🌈, sending SIGNALs to Zeno from HQ (tracker) over WebSocket, improving archiving of GitHub Issues and PR pages, etc.
What I didn’t ship (per the original proposal)
- Dummy test site. When I wrote the proposal, I hadn’t figured out a good E2E approach, so I planned a small httpbin-like site to help future E2E tests. After inventing the log-based method, this became unnecessary — the test code can spin up whatever web server it needs.
- Route items between a headless project HQ and a general project HQ conditionally.
Acknowledgments
- Google: for GSoC — it’s a great program.
- Internet Archive: thanks in many senses — Universal Access to All Knowledge!
- Dr. Sawood Alam, Will Howes, Jake LaFountain: my GSoC mentors — for reviewing my PRs and sharing many useful ideas. I learned lots of nifty web tricks.
- Corentin: the author of Zeno — no Zeno without him.
- Members of STWP:
- @OverflowCat: pointed me to other potential Go CSS parsers and fixed VS Code’s CSS variable highlighting; their blog “A New World’s Door” is full of high-tech CSS and became my testbed for Zeno’s CSS features.
- @renbaoshuo: the CSS lexer port is great.
- @NyaMisty: encouraged me a year ago to learn Go — opened a new world.
- @Ovler: revised my GSoC proposal PDF; helped uncover the conntrack issue.
- rod, goada, browsertrix-behaviors, and other libraries we depend on.
- Ladybird: not yet a usable browser, but the repo is small and easy to clone. Its code serves as a reference implementation for web standards. When the spec text is confusing, reading Ladybird helps — even though I barely know C++.