
夏天夏天悄悄过去,今年的 Google 编程之夏(Google Summer of Code, GSoC)即将结束,是时候赶在DDL(9月2日)前写份最终报告了。
先简单介绍一下 Zeno,Zeno 是 Internet Archive 的一个以 State-of-the-art 自称的 WARC web archiver,目前为止应该是唯一的 Golang WARC Archiver。不过与其称之为 SOTA,我更愿称之为开源拖拉机。
从哪儿开始说呢?先说最无意义的数据:从6月2日 GSoC 正式开始,到8月31日大约90天,我向 Zeno 发了25个PR:23 Merged,2 Open。外加 gowarc (Zeno 自己的 WARC 读写及录制 lib) 和 gocrawlhq (Zeno 的 tracker 的 client) 的两个 PR,以及对外部依赖的一些PR。
选取一些遇到的有意思的事情说道说道吧!
CSS,神话

正则仙人
总所周知,CSS 里可以引用外部的 URL 资源,比如这样给 body 加上背景图片:
body {
background: url(http://example.com/background.jpg);
}
Zeno 会解析 html 里面的 inline CSS,并且用正则尝试提取 CSS 中的 url-token 和 string-token 中的值。这两个简单的正则长这样
urlRegex = regexp.MustCompile(`(?m)url((.*?))`)
backgroundImageRegex = regexp.MustCompile(`(?:(['"]?)(.*?)(?:['"]?))`)
最大的问题就在于第二个 backgroundImageRegex 写得太宽松,只要是括号就匹配。
导致 Zeno 经常会从 HTML inline CSS 中解析出大量不存在的相对路径,例如 CSS color: rgb(12, 34, 56) 括号中的 12, 34, 56 会被 backgroundImageRegex 匹配,从而导致 Zeno 爬取一堆烦人的 404 的 url assests。
那这个问题怎么解决呢?写一个更完善的 regex ?我可不想当正则仙人,用个正经的 CSS Parser 来解析我们的各种 CSS 吧。
正经的 CSS Parser 应该能帮我们正确处理 CSS Token 转义等杂务。
有标准,没实现
在找 CSS Parser 之前,先要搞清楚一个问题——“对于存档爬虫来说,CSS 中哪些元素可能会包含有用的外部资源?”
翻阅目前的 CSS Values and Units Module Level 4 标准,其 Security Considerations 一节明确地说:
This specification defines the url() and src() functions (<url>), which allow CSS to make network requests.
不过呢,src() 由于安全考虑,现在还没有被任何浏览器实现,现阶段可以忽略不实现。
注意对于 @import 有个特殊情况,@import 后面的 string-token 应被视为 url(“”) 来解析,比如如下两条规则是等价的:
@import "mystyle.css";
@import url("mystyle.css");
因此 CSS 能自行产生网络请求(不借助 JS)的 token 只有 url() 和 @import 后面跟的 string-token。
url() 其实有两种:
- 一种是老的不带引号的:
url(http://exampl.com)这样的 url-token- 一种是带引号的(双引号单引号都可以):
url("http://exampl.com")这样的 function-token + string-token两者的解析方式和转义方式有差异。本文后续提及的 url-token 泛指两者。
Parser 拼好饭
搞清楚 CSS 标准后,找了一圈,Go 的各种 CSS Parser 库似乎也就 https://github.com/tdewolff/parse 这个库貌似有模有样的,用的人也多。但是上手实验了一下,现实给了我一耳巴子。
它没做 Token Value 的细提取,只是 lexer/tokenizer 粗切片,不太能用。
比如它只能提取出来 url( "http://a\"b.c" ) 这样的整个 Token,你输入啥它就输出啥,无法提取其中的 http://a"b.c 这样的转义后的值。
至于其它的 Golang CSS Parser,还不如它呢。
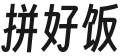
那我就写了个专用于处理 url-token 的值的小 parser,主要是处理转义、换行和空格。接着和 tdewolff/parse 拼一起就行了。
PR: #324 Replacing the regex-based CSS extractor with a standard CSS parser
再加上个状态机,提取 @import 引用的 URL。
需要注意 @import 只能出现在 css 的 header 里,其它地方出现的 @import 需要无效化。这个不实现都无所谓,但反正也不算复杂,就顺带做了。
PR: #339 Extracting URLs from CSS @import rule
生活在树上
在 Zeno 中,每个 URL 爬取任务被称为 item,每个 item 都有自己的类型和状态。
type Item struct {
id string // ID is the unique identifier of the item
url *url.URL {
mimetype *mimetype.MIME
Hops int // This determines the number of hops this item is the result of, a hop is a "jump" from 1 page to another page
Redirects int
}
status ItemState // Status is the state of the item in the pipeline
children []*Item // Children is a slice of Item created from this item
parent *Item // Parent is the parent of the item (will be nil if the item is a seed)
}简单说下,Hops 是页面深度,Redirects 是跳转次数。
而 item 之间则是树状关系,莫得妈老汉的根 item 被称为 seed item,对应“网页/外链”,而其它所有的子节点被称为 asset item,对应“资源”。
比如我们想存 archive.org,那么 archive.org 这个 item 就是 seed item。在这个页面上发现了 archive.org/a.jpg 这个 asset,把它添加到 item.children 中。还发现了 archive.org/about 这个 outlink,则新建一个树外的 seed item,这个新的树外 seed item 的 hops+=1。
而我们知道,HTML 不仅有 inline CSS,还有 <link rel="stylesheet" href="a.css"> 这样的单独 CSS 文件。
而 Zeno 之前遇到这种独立 CSS 的网页(大部分网页),就容易抓瞎,不仅因为缺 css parser,还因为 css 文件中的资源是作为 seed item (html) 的 asset item (css 文件) 的 asset——Zeno 一般情况下不会提取 asset 的 asset。
所以,我做的就是引入前面拼好的 Parser,再给 item.mimetype == CSS && item.parent.mimtype == HTML 的 asset item 开后门,允许其提取 item 中的 assets。(还需要给 HTML->CSS->CSS 这样的多个 CSS @import 链开后门,见后文)
这样就大功告成了吗?并不。
CSS Nesting
开发中发现 tdewolff/parse 不支持 CSS Nesting,这是一个 2013 年引入 CSS 的“新”语法特性。
为了能尽力解析加了 CSS Nesting 语法糖的 CSS,我只得继承正则仙人的衣冠,重新加上一个“更高明”的 regex fallback parser 在 tdewolff/parse 错误时兜底。
cGroup = `(.*?)`
cssURLRegex = regexp.MustCompile(`(?i:url(s*['"]?)` + cGroup + `(?:['"]?s*))`)
cssAtImportRegex = regexp.MustCompile(`(?i:@imports+)` + // start with @import
`(?i:` +
`url(s*['"]?` + cGroup + `["']?s*)` + // url token
`|` + // OR
`s*['"]` + cGroup + `["']` + `)`, // string token
)这样真的结束了吗?并不。
无止境地 @import
https://www.w3.org/TR/css-cascade-5/#at-ruledef-import 中如此写道:
The @import rule allows users to import style rules from other style sheets. If an @import rule refers to a valid stylesheet, user agents must treat the contents of the stylesheet as if they were written in place of the @import rule
这个 “in place” 就很有趣啊,这里很自然地让我想:“如果弄个会在 CSS 里无限递归 @import 的网页,浏览器会咋样?”,在 CSS 标准里也没看到有深度限制。那么现实的浏览器会像类似多重重定向那样限制最大 CSS @import 深度吗?
我实验了下:浏览器没有 @import 递归深度限制。
所以你甚至可以用 CSS 制造一个永远无法加载的网页,hhhh。
(这里有个视频,之后放这里)
所以,为了防止 Zeno 被 CSS @import DoS (尽管不太可能),我加了个 –max-css-jump 选项来限制递归深度。
PR: #345 Cascadingly capture css @import urls and extracting urls from separate css item
哦对了,CSS 标准规定:resolve 在单独的 CSS 文件中出现的 ref URL 时,应将 CSS 文件自身的地址作为 base URL,而非 html 文档的 base URL 位置。这个由于 Zeno 的 item 树的设计,正好符合了这个特殊的要求,因此 PR 中你找不到相关的代码。
不正经的 Firefox
本节内容与 Zeno 无关,仅是一个阅读 CSS 标准时注意到的一个不一致。觉得挺有意思的。
先看 string token 的转义处理标准。
U+005C REVERSE SOLIDUS (\)
1. If the next input code point is EOF, do nothing.
2. Otherwise, if the next input code point is a newline, consume it.
3. Otherwise, (the stream starts with a valid escape) consume an escaped code point and append the returned code point to the <string-token>’s value.
string token 的 \ 转义后面如果是 EOF,则啥也不做(相当于忽略这个转义,直接返回 token)
但是如果 \ 后面跟的是有效的 escape,则进入转义处理流程。
检测转义是否有效是取 \ 和下一个 code point: https://www.w3.org/TR/css-syntax-3/#check-if-two-code-points-are-a-valid-escape
If the first code point is not U+005C REVERSE SOLIDUS (), return false.
Otherwise, if the second code point is a newline, return false.
Otherwise, return true.
所以说对于 string token,只要下一个 code point 在不是 EOF 的基础上,还不是 newline ,就认为是有效转义。
转义处理是这样的: https://www.w3.org/TR/css-syntax-3/#consume-an-escaped-code-point
This section describes how to consume an escaped code point. It assumes that the U+005C REVERSE SOLIDUS () has already been consumed and that the next input code point has already been verified to be part of a valid escape. It will return a code point.
Consume the next input code point.
1. hex digit
Consume as many hex digits as possible, but no more than 5. Note that this means 1-6 hex digits have been consumed in total. If the next input code point is whitespace, consume it as well. Interpret the hex digits as a hexadecimal number. If this number is zero, or is for a surrogate, or is greater than the maximum allowed code point, return U+FFFD REPLACEMENT CHARACTER (�). Otherwise, return the code point with that value.
2. EOF
This is a parse error. Return U+FFFD REPLACEMENT CHARACTER (�).
3. anything else
Return the current input code point.
从后面的 code points 一个一个地取 hex,取最多 6 个 hex。
如果取到了 1-6 个 hex ,并且 hex 后面的 code point 是 whitespace,则把 whitespace 吞掉
为什么吞掉,详见: https://www.w3.org/International/questions/qa-escapes#cssescapes ,Because any white-space following the hexadecimal number is swallowed up as part of the escape)。
如果没有取到 hex ,则原样返回当前的 code point 。
如果遇到 EOF,则返回 U+FFFD。
这里的问题是,这个转义处理流程根本不会在 hex 数量为 0 时遇到 EOF 。如果 hex 数量为 0 ,则只可能是
3. anything else
这个情况,原样返回就行了……
因为在上一步的转义验证流程中,需要输入 \ 和下一个 code point 才能工作,所以排除了 code point 是 EOF 的情况。
所以最终问题来了。
我是遵守上层 Consume a token 的规则,如果 \ 后面的是 EOF,则啥也不做。还是遵守 escape rule,如果 \ 后面是 EOF,则解释为 U+FFFD 。
发现 2013 年的时候也有人发现了这个问题,对应的 issue 在:https://github.com/w3c/csswg-drafts/issues/3182
不只我恍惚,浏览器们也拿不定主意。
Chrome 和 Safari 觉得这种情况返回 � 。
Firefox 觉得返回 \� 。
之后 W3C 的决议是 「[EOF] turns into U+FFFD except when inside a string, in which case it just gets dropped.」
到现在,目前浏览器们在这点上面的行为也没统一。
这个问题对应的 wpt : https://wpt.live/css/css-syntax/escaped-eof.html
没有收到通知的 VS Code
参阅 @overflowcat 的博客文章:https://blog.overflow.cat/posts/css-variable/
Blink 先崛带动 Go 后崛
参阅 @renbaoshuo 的博客文章:https://blog.baoshuo.ren/post/css-lexer/
8月5号时,@renbaoshuo 突然说他把 Blink 的 css lexer 移植到了 golang,名为 go-css-lexer。相信读者从上文也知晓了现有的 Golang CSS Lexer/Parser 的库没几个能用的,所以不出意外的话,这是个简明可靠的好东西。
的确如此。
我稍微优化了下 go-css-lexer 的性能,用它替换掉了 tdewolff/parse 和正则 fallback,效果很好,CSS Nesting 和 custom css variable 都没有问题。
PR: renbaoshuo/go-css-lexer#1 Performance optimization
PR: #415 New CSS parser with go-css-lexer
Headless
两年前,在 Zeno#55 中,有过用 Rod 来做 headless 功能的尝试。
Rod is a high-level driver for DevTools Protocol. It’s widely used for web automation and scraping. Rod can automate most things in the browser that can be done manually.
但由于担忧 Chrome DevTools Protocol (CDP) 会在内部操纵网络数据(如:修改 http headers、透明解压 payload),#55 便被暂停了。
我在大概浏览 Rod 的 request hijacking 代码后,Rod 的 request hijacking 功能工作在 CDP 之外。我询问了 Rod 的开发者,得到了二次确认,确实可以让外部的 http.Client (我们的 GOWARC 库)完全控制 Chromium 的网络请求。
Hijacking Requests|Respond with ctx.LoadResponse():
* As documented here: <https://go-rod.github.io/#/network/README?id=hijack-requests>
* The http.Client passed to ctx.LoadResponse() operates outside of the CDP.
* This means the http.Client has complete control over the network req/resp, allowing access to the original, unprocessed data.
* The flow is like this: browser --request-> rod ---> server ---> rod --response-> browser用 CDP 来 mitm 比一般的 mitmproxy 方案的优势是可以更细粒度地操控每个 tab 发出的网络请求。
那就开干吧!我原本预期这个功能只需要花一周就能搞定,结果花了两个多月。主要是处理各种细节问题。
PR: https://github.com/internetarchive/Zeno/pull/356
滚屏
为避免多图杀猫,前现代时懒加载技术就已经普及了,更不用提现代 Web 各种 JS 动态加载了。
所以当页面加载完成后,第一件事是让浏览器滚屏触发各种资源的下载。这滚屏也是门学问:
- 每次滚动步进高度不能大于tab可见窗口的高度,不然可能遗漏一些元素。
- 滚太快,可能有些定速的动画来不及完全加载展示,资源失去加载机会。
- 滚太慢,降低对非懒加载或简单动态加载的长网页爬取效率。headless 太重了,网页在内存里多驻留一秒就是浪费。
- 要滚得丝般顺滑,不要卡顿。
琢磨会儿这个问题感觉有些复杂,也许其它支持 headless 的 web archiver 应该有类似的轮子。想起来 webrecorder 家的存档器会自动滚屏。果然,webrecorder/browsertrix-behaviors 里面包含一个简单的启发式滚屏策略,而且它还有很多其它非常有用的自动播放媒体、自动点击等功能。而且所有功能都打包成了个单 js payload,我可以直接用它,不造轮子了!
DOM
朴素传统的爬虫,一个请求得到一个 raw html,再嘎嘎处理就行。
但在浏览器世界中,一切都是 dom,一个标签页的 dom tree 是服务器返回的 html 响应、浏览器的 html normalization、JS的dom操作、甚至你的浏览器插件等等的共同作用的结果。
为了与 Zeno 现有的 outlink post-process 流程兼容,以便实现 outlinks crawl(提取标签页中的外链),于是将标签页导出为 html 作为临时的 item.body 以便现有的 outlink extractors 不作太多修改也能用于处理 headless 的 item。
nf_conntrack 惹祸
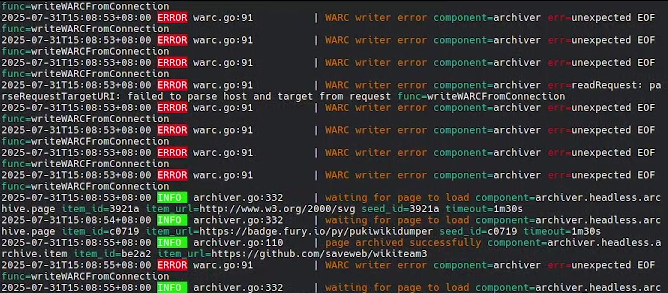
在搓完 headless 的 outlinks crawl 后。发现在高并发状态下,不一会儿就出现绝大部分新连接离奇的 Connection EOF 随后陷入死亡重试。由于现象非常像竞态,间断排查了一两周也没找到问题,本机的 dmesg 也没异常,fs.file-max 也是够的。
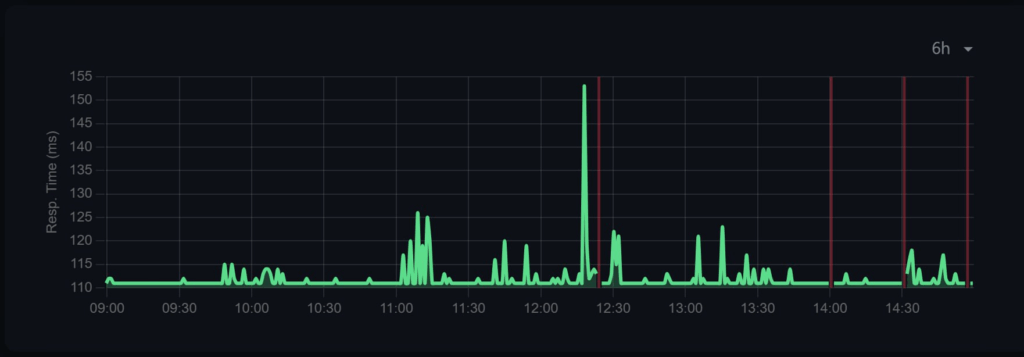
直到无意间发现我出网设备偶发的掉线时间点与我跑 Zeno Headless 测试的时间点吻合……
感谢 @olver 搭建的监控。

- gowarc 没有实现 HTTP/1.1 Keep-Alive (目前也不支持 HTTP2)
- Zeno 每个请求都会发起新连接。
- Conntrack 在连接关闭后,仍会将连接状态在它内部的表里保存一段时间。
- 出网设备内存只有512M,于是
nf_conntrack_max表容量被设为 4096。 - Zeno Headless 下,会产生巨量的请求。
- Conntrack 表打满之后会扔掉新连接,但已有连接不会受影响,我各种聊天软件也一直在线,我就没注意到异常。
在调高出网路由设备的 nf_conntrack_max 后,问题解决。
未来的工作:
有点担心 Zeno 高并发下也会快速消耗目标站点的 TCP 连接池。最好的解决方法很明显:实现连接复用。
- 支持 HTTP/1.1 Keep-Alive。
- 支持 HTTP2。
HTTP Caching
- Chromium 的 HTTP Caching (RFC 9111) 是在 net stack 中实现的。
- 我们通过 CDP 绕过了 Chromium 的 net stack 以使用我们 gowarc 的 http client。
导致每次访问页面都要重新下载可缓存的页面资源(js、css、images……),导致每个标签页都要重新下载各种资源。如果仅仅是为了减少不必要的流量消耗,在 Zeno 侧实现一个完整的 HTTP Caching 太复杂了。
幸好,CDP 在请求元数据中有资源类型属性。对图片、CSS、字体这样的请求,如果之前爬过,那我们就屏蔽就好了。而对于可缓存的静态 HTML、JS,由于它们是页面顺利加载所必须的,所以我们不得不放行它们。
isSeen := seencheck(item, seed, hijack.Request.URL().String())
if isSeen {
resType := hijack.Request.Type()
switch resType {
case proto.NetworkResourceTypeImage, proto.NetworkResourceTypeMedia, proto.NetworkResourceTypeFont, proto.NetworkResourceTypeStylesheet:
logger.Debug("request has been seen before and is a discardable resource. Skipping it", "type", resType)
hijack.Response.Fail(proto.NetworkErrorReasonBlockedByClient)
return
default:
logger.Debug("request has been seen before, but is not a discardable resource. Continuing with the request", "type", resType)
}
}这样虽然没有实现完整的 HTTP Caching 那样“标准”,而且会让 headful 模式下的页面实时预览看起来缺胳膊少腿。但简单有效,不影响 replay 质量。按照 HTTP Archive: Page Weight 的统计数据,草率计算一下,应该能节约大约 44% 的流量。
未来的工作:
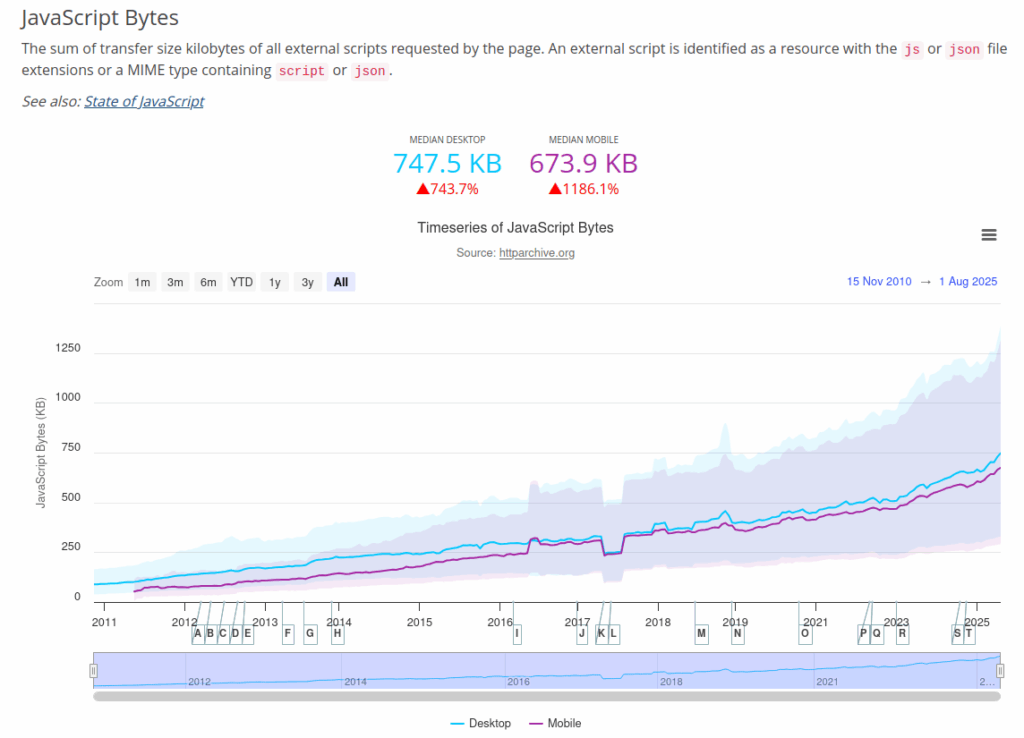
相比其它类型的网络资源,近年来 JS 的大小隐隐有加速上升的趋势。
未来可以在 Zeno 中为 headless archiver 实现 HTTP Caching,节约这类 JS 流量。
Chromium revision
Rod 默认的 Chromium revision 太老了,所以我改成从 chromiumdash.appspot.com 拿到最新 Chromium 的快照 revision 号,接着下载对应版本的二进制。
结果发现 Google 有时候会在 chromiumdash 上释出版本号,但不 build 二进制放进 repo 里。
只好像 Rod 那样,在 Zeno 中 pin 住默认的 revision 号。
以及发现部分网站的 WAF 会阻止 snapshot 版的 Chromium,但是对于 release 版的 Chromium (来自发行版)则无动于衷。因此对于生产环境,我们最好用发行版打包的 Chromium 二进制。
Q: 为什么不用 Chrome 二进制呢?
A: Zeno 是 AGPL 开源项目,而 Google Chrome 不是。多少有点膈应。Q: 难道 Google 没有 release 版本的 Chromium 吗?
A: 只有自动化的快照版本。
Content-Length 与 HTTP Connection
当 Zeno 开始爬虫作业后,如果磁盘空间不足,diskWatcher 会发出信号暂停 workers 处理新 item ,但正在进行下载的 workers 会继续下载直到完成。
如果 diskWatcher 发出暂停信号时,workers 正在下载的总资源大小大于 –min-space-required 阈值,我们就会用完存储,随即世界毁灭。
所以我引入了 –max-content-length 参数,在下载前检查 Content-Length header 有没有超,超了就跳过下载。对于大小未知的流式响应,如果已下载的大小大于 –max-content-length,同样取消下载。
PR: https://github.com/internetarchive/Zeno/pull/369
这 PR 写着写着,发现 gowarc 与连接相关的代码有三处 bug:
- 一个非常严重的 bug:gowarc 在 HTTP TCP Conn 层出现异常关闭时 (early EOF, io timeout, conn closed/reset),由于没有向下 .CloseWithError(),而是调用常规的 .Close(),导致下层的 MITM 套娃 HTTP TCP Mirrored Conn 以为是正常 EOF,最终导致,对于没有 Content-Length 头的流式响应,这类 early EOF 的响应被当成正常响应而被写入了 WARC 存档中,导致所有流式响应的数据完整性都失去保证了。(而对于更常见的非流式响应,由于存在 Content-Length,即使 early EOF 仍然被当成了正常 EOF,但是由于 go 的 http 标准库的 http.ReadRespon() 会用 io.LimitReader 来组装 Response.Body ,这样的 Response.Body 会自己做一次额外的 EOF 位置与 Content-Length 位置的匹配检查,如果不匹配会返回 early EOF。换句话说,这 BUG 在大部分情况下被标准库缓解了导致我们没发现)。
--http-read-deadline没有任何效果。- 发生错误时,在一些情况下,临时文件没有被删除。
具体见 PR 的描述: https://github.com/internetarchive/gowarc/pull/115
未来的工作:
我原本还准备引入 –min-space-urgent 功能,在磁盘容量危急时,中断所有 workers 的下载。但修完 bug 太兴奋,就忘了,哈哈。以后再做以后再做。
E2E Test
爬虫面对的是真实的互联网,而 Zeno 以前只有 unit test,没有拉通各种组件一起跑的集成测试或 E2E 测试。
听闻 Kubernetes 的 E2E test 是 Golang 届的榜样,但我瞪着 https://github.com/kubernetes-sigs/e2e-framework 看也没看出个明堂,看不懂。我还是不知道怎么给 Zeno 写 E2E test:怎么插桩,怎么知道各组件按预期运行呢?
我琢磨出个不知道个实现 E2E 方法——用日志来实现。我想不出其它非侵入式的实现方法了。
做法就是,go test 测试时把 Zeno 主程序拉起来,让 Zeno 把日志重定向到某个 socket,再让 Zeno 去自由地执行我们要喂给它的测试任务。
测试套件连上 socket 拿到日志流,随后一行一行地 assert 日志里有没有我们预期/不预期的内容。
这个方法好在不需要插桩或者 mock 任何东西,日志即桩。
为了拿到 coverage 和让 -race 之类的 go test 功能能覆盖到被测试的主程序,所以不能 execve 主程序的二进制起新进程。需要在 Test* 函数里调用主程序的入口函数来把主程序拉起来。
由于 go test 会把同一个 package 的 _test.go 里的全部 Test 函数都编译到同一个二进制、在同一个进程里跑测试,所以需要把每个 E2E test 写到不同的 package 里。
PR: https://github.com/internetarchive/Zeno/pull/403
后来意识到因为都在一个进程里,不需要 socket 来“跨进程”通讯,于是后续把上面的 socket 换成了更简单的 io.Pipe 。
把头从 UTF-8 的沙子里探出来
没有所谓的纯文本。不知道编码的字符串是没有意义的。你不能像鸵鸟一样再把头埋在沙子里,假装「纯」文本是 ASCII。——The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!) – Joel on Software
截至 2025-08-30,全世界 98.8% 的网页是 UTF-8 编码的。而 Zeno 此前并没有特别地处理非 UTF-8 的 html。
如果 Zeno 只是个一般用途的 web crawl,我们大可忽略这仅有的 1.2% 非 UTF-8 的网页。但 Zeno 是一个 web archiver,而这些仍然使用着遗留字符编码且存活到现在的网站,任何 web archivist 都会同意它们的存档价值很高,很复古。
功能实现起来比较简单,按照 whatwg 的标准按部就班地实现并写好测试,就好了。
从 whatwg 的标准中也能闻到浓浓的浓郁的 legacy 气息:
https://html.spec.whatwg.org/multipage/urls-and-fetching.html#resolving-urls
Let encoding be UTF-8.
If environment is a Document object, then set [encoding] (document charset) to environment's character encoding.
https://url.spec.whatwg.org/#query-state
Percent-encode after encoding, with [encoding], buffer, and queryPercentEncodeSet, and append the result to url’s query.
https://url.spec.whatwg.org/#path-state
...special cases...
Otherwise, run these steps:
.... special cases ...
3. UTF-8 percent-encode c using the path percent-encode set and append the result to buffer.如果 document charset 是非 utf-8 编码,则 encode url 时,需要对 url path 用 utf-8,对 url query 用 document 的 charset。是不是有点奇葩?哈哈。
PR: https://github.com/internetarchive/Zeno/pull/370
Goada
ada 是一个 C++ 写的兼容 WHATWG 标准的 URL Parser,它也提供 Go Binding:goada。Zeno 用它来 normalize URL(Golang 的 net 标准库的 URL 解析实现与 WHATWG 并不兼容),但 goada 毕竟是一个 C++ 库,所以我们编译 Zeno 的时候也不得不启用 CGO,这样交叉编译 Zeno 就有点麻烦了。
@otkd 尝试过用 pure go 的 https://github.com/nlnwa/whatwg-url 替换 goada (Zeno#374),但我发现 whatwg-url 解析到非 utf-8 字符会简单粗暴地将其替换为� U+FFFD 再百分号编码,而不是对字符直接按 byte 原 HEX 来百分号编码。
我们在 normalizing 前无法保证 Zeno 拿到的 URL 是不是有效 utf8 字符串,而且我们对非 utf-8 的 html 和 url 的 encoding 需要 URL Parser 有按 byte 原义来百分号编码的行为(这也是 WHATWG 标准所要求的),所以 #374 就被关闭了。
未来的工作:
goada 作为一个 URL Parser 的质量非常好,如果它能摆脱 CGO 的话就更好了。未来可以尝试用 ncruces/go-sqlite3 的 wazero 这样的方案把 ada 打包成 wasm 来避免 CGO。
杂项
剩下的就是一些小 PR 了,不值一提。例如给终端加颜色🌈、支持从 HQ (tracker) 端通过 websocket 发 SIGNAL 给 Zeno、改进 GitHub Issues 和 PR 页面的存档效果之类的,不太能拿出来吹嘘。
各种未来的工作
(待补充)
GSoC 最终成果
(这里会有一些 GSoC 前后的 Zeno 存档各类网页的效果的直观的对比图,还有 headless 的视频)
致谢
- Google:提供了 GSoC 这个非常好的活动。
- Internet Archive:各种意义上的感谢,Universal Access to All Knowledge!
- Dr. Sawood Alam, Will Howes, Jake LaFountain:作为我的 GSoC 导师,review 我的 PR,给了我很多有用的建议,我学到了好多妙妙 web 小技巧。
- Corentin:Zeno 的作者,没有他就没有 Zeno。
- STWP 的成员们:
- @OverflowCat:猫帮我喵了其它潜在可用的 Golang CSS Parser,还修了 VSC 的 CSS 变量高亮;猫的博客《新世界的大门》充满了各种高科技 CSS,成为了我测试 Zeno 的 CSS 功能的试验场。
- @renbaoshuo:移植的 CSS Lexer 好用。
- @NyaMisty:一年以前推荐我学学 Golang,让我打开了新世界的大门。
- @Ovler:修订了我的 GSoC Proposal PDF;帮助发现了 conntrack 引起的诡异问题。
- rod、goada、browsertrix-behaviors、pdfcpu、tdewolff/parse 等各类我们使用的依赖库。
- Ladybird:ladybird 作为一个浏览器还不算可用,但它仓库不大,容易 git clone 下来,它的代码可以作为 web 标准的参考实现,看不懂 web 标准里的说法时就看看 ladybird 的实现,虽然我对 C++ 也完全不熟。
点赞